����һ�������x���}
����(1)B���������㷨�Ŀ��ƽY���o�����㷨�Ļ��������������H�Q�����㷨�и������Ĉ���������������Ҳֱ�ӷ�ӳ���㷨���OӋ�Ƿ���ϽY����ԭ�t���һ���㷨һ�㶼���������ѭ�h�������x�����N�������ƽY���M�϶��ɡ����}�𰸞�B��
����(2)C���������ʽ�惦�Y���˷������惦�Y����ȱ�c�����Ĺ��c���g���ԄӑB��Ո��ጷ�;���Ĕ���Ԫ�ص�߉�����c��ָᘁ�ָʾ��������Ҫ�ƄӔ���Ԫ������������ʽ�惦�Y���µľ��Ա����ڲ���̈́h������������}�𰸞�C���
����(3)C����������������Ļ���˼���ǣ�ͨ�^һ����������ӛ䛷ָ�ɪ����ăɲ��֣�����һ����ӛ䛵��P�I�־�����һ����ӛ䛵��P�I��С�������ٷքe���@�ɲ���ӛ��^�m�M�������������_��������������;��������Ļ���������ָ���o��������������еĸ�Ԫ�����β��뵽�ѽ�����ľ��Ա��У��Ķ��õ�һ���µ�����;�x������Ļ���˼���ǣ������������Ա��������x����С��Ԫ����������������Q��������ǰ��(�@�������е�λ��)������Ȼ��ʣ�µ��ӱ�����ͬ�ӵķ�����ֱ�����՞�ֹ;�w�������nj��ɂ���ɂ����ϵ�������M�ϳ�һ���µ�����������}�𰸞�C�����
����(4)A��������ܛ�����̰���3��Ҫ�أ��������������ߺ��^������������}�𰸞�A��
����(5)B���������Y���������ij��ù����Д������D�������ֵ������ж�����ж��������������̾W�dz�Ҋ���^���OӋ�����еĈD���OӋ�����}�𰸞�B���
����(6)A��������ܛ���İМyԇ�����ǰќyԇ������һ�����_�ĺ���������������S�yԇ�ˆT���ó���Ȳ���߉�Y�������P��Ϣ���OӋ���x��yԇ���������������������߉·���M�Мyԇ���������}�𰸞�A��
����(7)C�����������ļ�ϵ�y������������ӛ���Ȳ��Y���������ʽ�ǵ��L����ͬ��ʽ��ӛ䛵ļ����������ɴ惦���g�������M�������������ʹ����������ڔ�����ϵ�y��������������ǽY��
��������������@�N�Y����Ҫ�������������r���H������������������߀Ҫ���������g���Pϵ���@����ͨ�^�����ض��Ĕ���ģ�́팍�F����������}�𰸞�C��
����(8)D������������ģ���������ă�����3�����������������ǔ����Y�����������������͔����s������������������������ģ���еĔ����Y����Ҫ��������������������ݡ����|��������Լ��������ϵ��;����������Ҫ�����������������Y���ϵIJ�������c������ʽ�������}�𰸞�D�����
����(9)A���������Ӵ�ģ��������lչ�����Ĕ�����ģ���������Ļ����Y���ǘ��νY�����@�N�Y����ʽ�ڬF�������к��ձ飬�����Y����������M���C����������������¡��Ӵη������Pϵģ�����ö��S������ʽ��ʾ���w�͌��w�gϵ�Ĕ���ģ������Pϵģ�͵����c���£��Pϵģ���c���Pϵģ�Ͳ�ͬ����������ǽ����ڇ���Ĕ��W������A�ϵ�;�Pϵģ�͵ĸ����һ���oՓ���w���w֮�g��ϵ�����Pϵ��ʾ;��ȡ·�����Ñ���;�Pϵ�����Ҏ�������Pϵ��
����(10)C��������������߉�OӋ����Ҫ�����nj�E��R�D�D�Q��ָ����RDBMS�е��Pϵģʽ��
����(11)B�����������Pϵ������ϵ�y�У��������еĔ����惦�ڶ��S�������������ӛ䛘��������ÿ��ӛ䛶�������ͬ�ĽY�����������ÿ��ӛ��������Č��������ͬ����ȡֵ��ͬ�������˿��Կ϶��������е�ӛ�֮�g����ϵ���������еĔ����������Ҳ���Ƕ��S�����ֶ�����������ڔ�����ı�������ͨ�����O��ij���ֶλ�ijЩ�ֶΞ��I����ͨ�^�@Щ�I�Ϳ��Դ_�������ֶε�ֵ�����������еĔ����֮�gҲ����һ�����Pϵ�����������Pϵ�͔�����ϵ�y�У�������Ĕ����֮�g��ӛ�֮��������ϵ�������_�𰸑�ԓ���x�B���
����(12)D���������������M�������ʽ�ЃɷN��
����DIMENSION<���M��>(<������1>[��<������2])[...]
����DECLARE<���M��>(<������1>[�������<������2])[...]
�����ɷN��ʽ�Ĺ�����ȫ��ͬ��������M���������ϵ�y�Ԅӽoÿ�����MԪ���x��߉��(.F.)ֵ��
����(13)D�������������p��̖�\������^�ɂ��ַ����r��ֻ�Ю��ɂ��ַ�����ȫ��ͬ(���ո��ַ���λ�á���С��)�������\��Y���Ş�߉���������DTOC()���������nj������͔��������ڕr�g�͔��������ڲ����D���ַ���������DTOC({^09/13/2012 08��O0��O0})�ĽY���ǡ�09/1 3/2012���������
����(14)C�����������^���ɱ�������Щ�������κΔ�����ı�������t��h FoxBase�����ڰ汾��FoxPro�����Ĕ������ļ������ɱ����������Ԍ����ɱ����˵��������������Ҳ���Ԍ��������еı��Ƴ������ɞ����ɱ����������������c���ɱ������^�e�ǃ����ֶ���������ַ�������ͬ�����������������ֶ���������ַ�����l28���������ɱ����ֶ���������ַ�����10��
����(15)D��������G0����ֱ�ӌ�ӛ��M�ж�λ��TOP�DZ��^����ʹ�������r����ӛ�̖��l��ӛ�����ʹ�������r����������������ǰ�������������ӛ䛡�BOTTOM�DZ�β�������ʹ�������r��ӛ�̖�����Ǘlӛ��������ʹ�������r���������������������헌�����ӛ䛡�GOT0��������ֱ�Ӷ�λ���ڎחlӛ������
����(16)C���������c������ͬ�ĽY�������ڱ����_�r���܉��ԄӴ��_�����nj��ڷǽY����������������ʹ��֮ǰ���_�����ļ���
�����Ϊ���.idx������һ�N�ǽY��������;���÷�Ĭ�J����.cdx���������Ҳ�ǷǽY���ͺ�����;�c����ͬ����.cdx�������ǽY���ͺ������������
�����Y���ͺ����������������ԣ��ڴ��_��r�ԄӴ��_;ͬһ�����ļ����ܰ�������������������������P�I��;�����ӡ����Ļ�h��ӛ䛕r�ԄӾS�o���������
����(17)D���������������������µ��B�Y�ֶ�ֵ�Ԅ����ӱ��е����P����ӛ�������������ơ��������ӱ��������P��ӛ���������t��ֹ�ĸ����е��B�Y�ֶ�ֵ��������ԡ����������������ԙz�鼴�h��������ӛ䛕r�c�ӱ�o�P����
����(18)C��������ʹ�ô��������x�����^��ʽ�飺sE. LECT<�����^>|<�e��>��
����<�����^̖>��ȡֵ������0��32767��������ȡֵ��0���t�x����δʹ�õ����������̖��С��һ�������^������
����<�e��>��ָ���_���Ąe�����Á�ָ���������_���Ĺ����^����e����3�Nʹ�÷�����
����ʹ��ϵ�yĬ�J�Ąe��A��J��ʾǰ10�������^;
����ʹ���Ñ����x�Ąe������������x��ʽ�飺USE����ALIAS�e��;
�����Ñ�δ���x�e���r��ֱ��ʹ�ñ�������e��������
������������Ҫ���ָ�����_�Ĺ����^����Z���飺USE<����> IN<�����^̖>�������˕r������׃��ǰ�^��λ��������
����(19)B�����������}�����SQL�Z���и��N�Z������ɵĹ��ܣ��±��o����SQL�г�Ҋ��һЩ����Ĺ�������
����
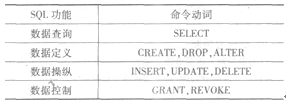
����(20)D�����������}��Ҫ����Ǚz��Ӌ��Cϵ�ČW���������Ҫ��Where�l����Ժϵ=��Ӌ��Cϵ��;����z���Y��ֻҪ�W̖������������SELECT�W̖�����������������˱��}����D���
�������P���]��
����2014��Ӌ��C�ȼ���ԇ�r�g�{��֪ͨ
����2014��Ӌ��C������ԇVFP���c�����R��
������ԇ�����]��2014��3��Ӌ��C������ǰ�_�̂俼���}








